

こんにちは、とめです。
データ分析を独学で学び、未経験からデータアナリストへ転職し、今では本業をやりながら、副業でも活動しています!
データ分析を勉強しようと思ったんだけど、SQLって難しそうでどこから始めたらいいか分からないんだよね…
そんな時はまずSQLの基礎を押さえてみよう!
SQLを独学で学ぶとき、多くの人は「専門用語が多すぎて挫折した」「環境構築が面倒で諦めた」とつまずきがちです。
その対策としておすすめなのが、SQLの基礎を体系的に理解し、シンプルなサンプルDBで動かして学ぶことです。
SQLの基礎とは、「どんなデータを抽出し、どう集計し、どう組み合わせるのか」を理解することです。
どんな映画にも台本があるように、データ分析にもSQLという台本が必要です。
分析に慣れてくると直感でSQLを書けるようになりますが、初心者のうちは基礎構文をしっかり押さえましょう。
- Sデータ分析でSQLが必要な理由
- SQLの基本
- SQLの基本構文
私もSQLの基礎を学んでから、データ分析がSQLがなんとなく分かってきたよ!
まだ、SQLの環境構築・準備ができていない方は、下記の記事で環境構築方法を解説しているので参考にしてください。


データ分析でSQLが必要な理由

SQLは、いわばデータ分析の設計図です。
SQLを使わずにExcelや手作業だけでデータ分析をしようとすると、どうしても問題が起こりがちです。
- データ量が多いと処理が重くなる
→ 作業効率が下がる - 複雑な集計や条件分けが難しい
→ 誤った分析につながる - 同じ処理を毎回やり直す必要がある
→ 分析に時間がかかる
一方で、SQLを使えば必要なデータを瞬時に抽出でき、正確でスピーディーな分析が可能になります。
SQLを使うことで、データ分析の精度もスピードも大きく上がるんだね!
SQLの基本

SQLの解説に入る前に、改めてSQLの基本を再確認しましょう。
SQLの基本的な役割は、以下3つに分かれています。
- 抽出
- 集計
- 結合
以上を頭に入れた上で、SQLの基礎構文を学んでいきます。
SQLの基礎構文

最初に覚えておきたい基礎構文は、以下のとおりです。
- SELECT(抽出)
- WHERE(条件指定)
- ORDER BY(並べ替え)
- GROUP BY(集計)
- HAVING(集計条件)
- JOIN(テーブル結合)
- DISTINCT・NULLの扱い
①:SELECT(抽出)
まずは、どの列(カラム)を取り出すかを明確にしましょう。
選ぶ列によって結果の見やすさが変わるため、必要な情報だけを指定して抽出します。
今回は具体例として、「usersテーブル」からnameとageを抽出するSQLを書いてみます。
SELECT name, age
FROM users;上記のSELECT文を実行した際に、以下のエラーが出た場合、
ERROR 1046 (3D000): No database selectedデータベースとテーブルを準備して選択する流れが必要です。
準備ができていないと、このようなエラーが出てしまいます。
このエラーが出た場合は、以下の手順で進めましょう。
- データベースを作成する
CREATE DATABASE sampledb;- 作成したデータベースを選択する
USE sampledb;- テーブルを作成する
CREATE TABLE users (
id INT AUTO_INCREMENT PRIMARY KEY,
name VARCHAR(50),
age INT
);- データを挿入する
INSERT INTO users (name, age)
VALUES
('Taro', 25),
('Hanako', 30),
('Ken', 22);- SELECT文を実行する
SELECT name, age
FROM users;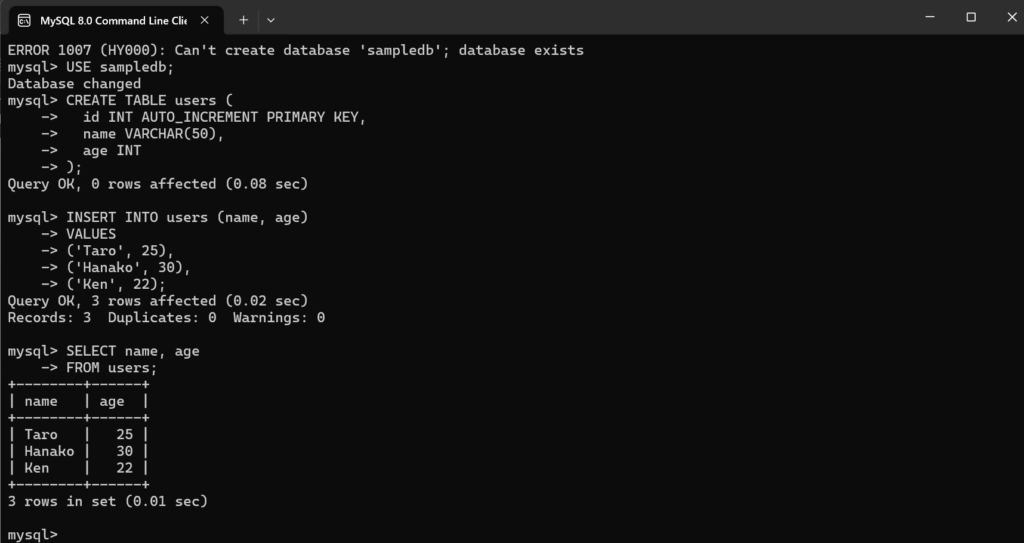
この手順で、作成したデータを抽出することができます。
②:WHERE(条件指定)
抽出したデータに条件をつけて絞り込むときに使うのがWHEREです。
基本形は次の通りです。
SELECT 列名
FROM テーブル名
WHERE 条件;▼例:25歳以下のユーザーだけを取り出す場合
SELECT name, age
FROM users
WHERE age <= 25;▼実行結果
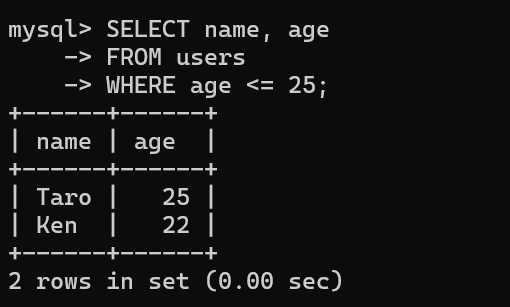
| name | age |
|---|---|
| Taro | 25 |
| Ken | 22 |
年齢を条件指定するやり方は分かったけど、名前で条件指定したい場合はどうすればいいの?
いい質問だね!
名前を条件指定したい場合は、以下の通りだよ!
▼例:特定の名前(Hanako)を指定する場合
SELECT name, age
FROM users
WHERE name = 'Hanako';▼実行結果
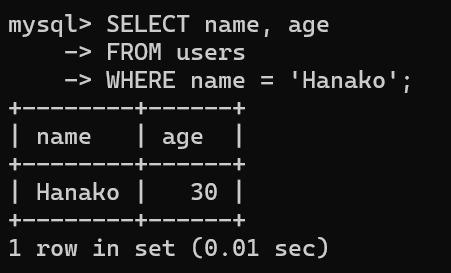
| name | age |
|---|---|
| Hanako | 30 |
なるほど!列名を指定してあげれば、その条件で絞り込めるんだね!
そう!“データ全体 → 必要なものだけ” って流れで考えると理解しやすいよ!
③:ORDER BY(並べ替え)
ORDER BYは、抽出したデータを昇順(ASC)や降順(DESC)で並べ替えるときに使います。
基本形は次の通りです。
SELECT 列名
FROM テーブル名
ORDER BY 列名 ASC | DESC;▼例:年齢を昇順(小さい順)に並べ替える場合
SELECT name, age
FROM users
ORDER BY age ASC;▼実行結果
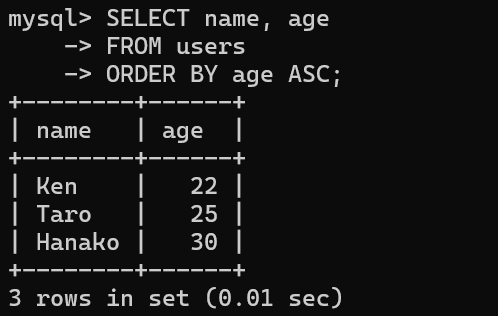
| name | age |
|---|---|
| Ken | 22 |
| Taro | 25 |
| Hanako | 30 |
大きい順に並べ替える場合は、以下の通りだよ!
▼例:年齢を降順(大きい順)に並べ替える場合
SELECT name, age
FROM users
ORDER BY age DESC;▼実行結果

| name | age |
|---|---|
| Hanako | 30 |
| Taro | 25 |
| Ken | 22 |
2つ以上の複数の条件で並べたい場合もできるの?
できるよ!
やり方は、以下の通り!
例えば、複数の条件でdepartment(部署)ごとに昇順、さらに ageを降順に並べたいときは、次のように書きます。
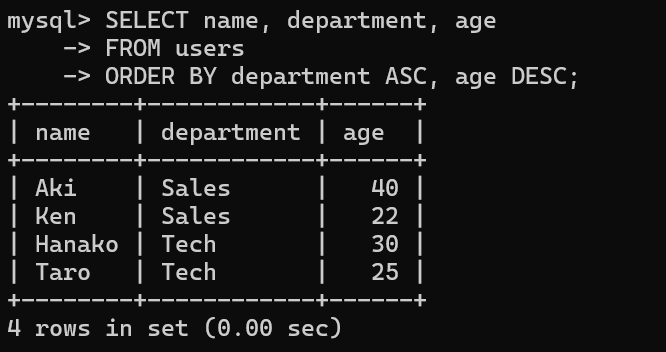
▼例:department(部署)ごとに昇順、さらに ageを降順に並べたい場合
SELECT name, department, age
FROM employees
ORDER BY department ASC, age DESC;エラーが出た場合は、「department」の列がないから!
以下のコードをコピーして実行しよう!
既存のテーブルに「department」列を追加するには、以下のコードを入力してください。
DROP TABLE users;
CREATE TABLE users (
id INT AUTO_INCREMENT PRIMARY KEY,
name VARCHAR(50),
age INT,
department VARCHAR(50)
);
INSERT INTO users (name, age, department)
VALUES
('Taro', 25, 'Tech'),
('Hanako', 30, 'Tech'),
('Ken', 22, 'Sales'),
('Aki', 40, 'Sales');▼実行結果
| name | department | age |
|---|---|---|
| Aki | Sales | 40 |
| Ken | Sales | 22 |
| Taro | Tech | 25 |
| Hanako | Tech | 30 |
おお!ORDER BYを使うと見やすい順番に並べ替えられるね!
そう!特に分析では “上位10件” みたいに並び替えて使うことが多いから便利だよ!
GROUP BY(集計)
データをグループごとにまとめて計算するときに使うのがGROUP BYです。
Excelの「ピボットテーブル」に近いイメージで、何を1行にまとめるか(粒度) を決めるのがポイントです。
基本形は次の通りです。
SELECT 列名, 集計関数
FROM テーブル名
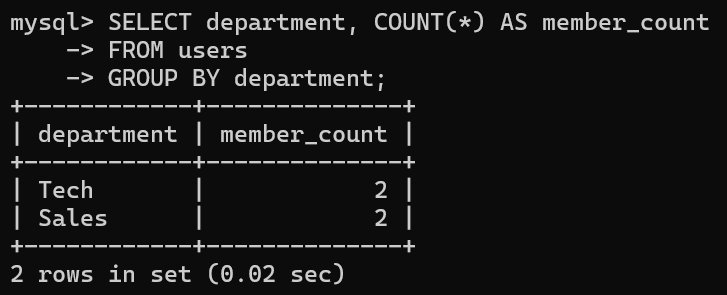
GROUP BY 列名;▼例:部署ごとの人数を数える場合
SELECT department, COUNT(*) AS member_count
FROM users
GROUP BY department;▼実行結果
| department | member_count |
|---|---|
| Sales | 2 |
| Tech | 2 |
平均年齢を求めることってできるの?
GROUP BY(集計)で簡単にできるよ!
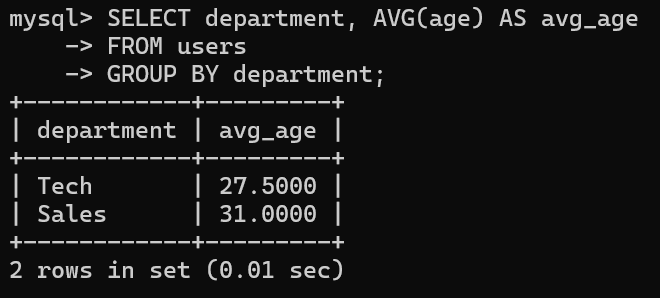
例えば、「部署ごとの平均年齢を求めたい」場合は、以下のように書きます。
▼例:部署ごとの平均年齢を求める場合
SELECT department, AVG(age) AS avg_age
FROM users
GROUP BY department;▼実行結果
| department | avg_age |
|---|---|
| Tech | 27.5 |
| Sales | 31.0 |
GROUP BYで、色んな集計の仕方ができるんだね!
その通り!
例えば“部署ごと”とか“月ごと”とか、いろんな条件で集計ができるよ!
HAVING(集計条件)
HAVINGは、GROUP BYでまとめた結果に対して条件をかけるときに使います。
WHEREとの違いは、WHEREは集計前のデータに条件をかけるのに対し、HAVINGは集計後のデータに条件をかける点です。
基本形は次の通りです。
SELECT 列名, 集計関数
FROM テーブル名
GROUP BY 列名
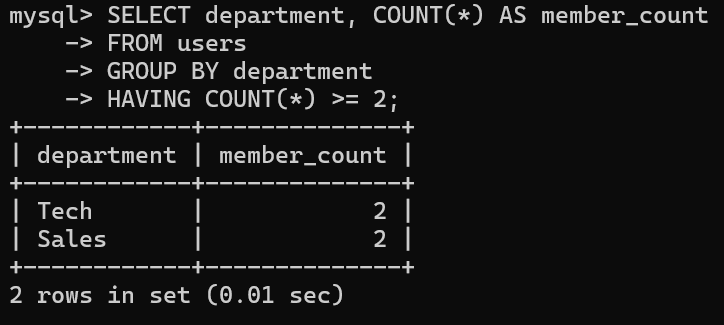
HAVING 条件;▼例:人数が2人以上いる部署だけを表示したい場合
SELECT department, COUNT(*) AS member_count
FROM users
GROUP BY department
HAVING COUNT(*) >= 2;▼実行結果
| department | member_count |
|---|---|
| Tech | 2 |
| Sales | 2 |
平均年齢が〇〇歳以上の部署を表示みたいなのもできるの?
簡単にできるよ!
例えば、「平均年齢が30歳以上の部署だけを表示したい」場合は、以下のように書きます。
▼例:平均年齢が30歳以上の部署だけを表示
SELECT department, AVG(age) AS avg_age
FROM users
GROUP BY department
HAVING AVG(age) >= 30;▼実行結果
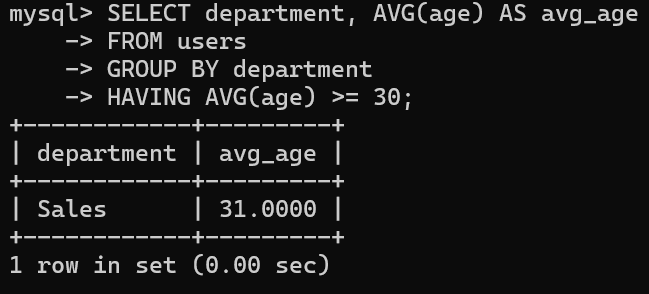
| department | avg_age |
|---|---|
| Sales | 31.0 |
WHEREとHAVINGって似てるけど、使い分けは“集計前か集計後か”なんだね!
その通り!集計条件を絞りたいときはHAVINGを忘れずに使おう!
JOIN(テーブル結合)
JOINは、複数のテーブルを組み合わせて1つの表にするときに使います。
Excelで言えば「VLOOKUP」に近く、共通のキー(IDなど)を使って情報をくっつけるイメージです。
基本形は次の通りです。
SELECT テーブル1.列名, テーブル2.列名
FROM テーブル1
JOIN テーブル2
ON テーブル1.共通列 = テーブル2.共通列;ここで言う【テーブル1】は、上記で作成してきたテーブルのことを指します。
【テーブル1】本記事で作成してきたテーブル
-- users(既存のテーブル)
id | name | age | department
---+--------+-----+-----------
1 | Taro | 25 | Tech
2 | Hanako | 30 | Tech
3 | Ken | 22 | Sales
4 | Aki | 40 | Sales【テーブル2】というのはこれから【テーブル1】とJOINでくっつけるためのテーブルを新たに作成するテーブルのことを指します。
今回は例として、以下のようなテーブルを作成していきます。
【テーブル2】これから作成するテーブル
-- orders(新しく作るテーブル)
id | user_id | product | amount
---+---------+-----------+-------
1 | 1 | Laptop | 1200
2 | 2 | Mouse | 20
3 | 3 | Keyboard | 50
4 | 4 | Monitor | 300この【テーブル2】の作成方法は以下のサンプルデータをコピーして作成してください。
▼サンプルデータ:ordersテーブル
CREATE TABLE orders (
id INT AUTO_INCREMENT PRIMARY KEY,
user_id INT,
product VARCHAR(50),
amount INT
);
INSERT INTO orders (user_id, product, amount)
VALUES
(1, 'Laptop', 1200),
(2, 'Mouse', 20),
(3, 'Keyboard', 50),
(4, 'Monitor', 300);これで2つのテーブルが作成できた状態になったよ!
因みにusers.idとorders.user_idが「共通のキー」になるから覚えておこう!
- usersテーブル:ユーザーの基本情報(名前・部署・年齢)
- ordersテーブル:ユーザーごとの注文情報(商品・金額)
また、JOINには種類がいくつかあります。
今回は、2種類のJOINの紹介と使い方を解説していきます。
- INNER JOIN:両方のテーブルにデータがあるものだけを表示(共通部分)
- LEFT JOIN:左側のテーブルを基準にして、右にデータがなくても残す
▼例:INNER JOIN(共通部分だけ)の使い方
SELECT users.name, users.department, orders.product, orders.amount
FROM users
INNER JOIN orders
ON users.id = orders.user_id;▼実行結果
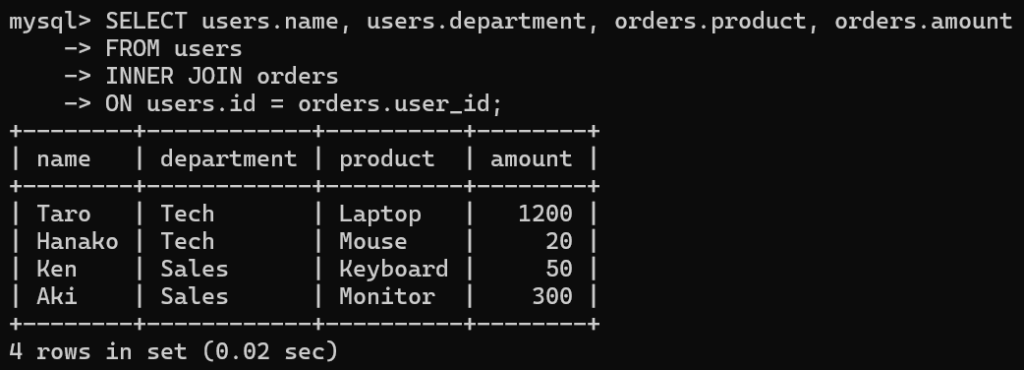
| name | department | product | amount |
|---|---|---|---|
| Taro | Tech | Laptop | 1200 |
| Hanako | Tech | Mouse | 20 |
| Ken | Sales | Keyboard | 50 |
| Aki | Sales | Monitor | 300 |
▼例:LEFT JOIN(左側を基準に全件表示)の使い方
まず、注文をしていないユーザーを追加してみましょう。
INSERT INTO users (name, age, department)
VALUES ('Mika', 28, 'Tech');その状態でLEFT JOINを実行します。
SELECT users.name, users.department, orders.product, orders.amount
FROM users
LEFT JOIN orders
ON users.id = orders.user_id;▼実行結果
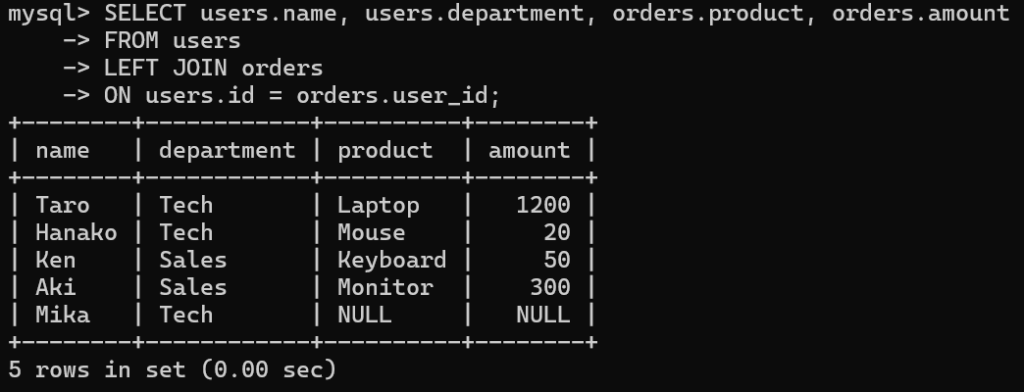
| name | department | product | amount |
|---|---|---|---|
| Taro | Tech | Laptop | 1200 |
| Hanako | Tech | Mouse | 20 |
| Ken | Sales | Keyboard | 50 |
| Aki | Sales | Monitor | 300 |
| Mika | Tech | NULL | NULL |
ordersに対応するデータがなくても、users側は残ります。
なるほど!
INNER JOINでは出てこなかった“注文していないMikaさん”が、LEFT JOINでは表示されて、商品と金額がNULLになってる!
INNERは“共通部分だけ”、LEFTは“左を全部残す(対応がなければNULLになる)”って理解しておけばバッチリだよ!
DISTINCT・NULLの扱い
SQLでは「重複を消したい」「空欄(NULL)を扱いたい」という場面がよくあります。
ここではよく使う2つのポイントを紹介します。
- DISTINCT(重複を排除)
- NULL(空欄の扱い)
DISTINCT(重複を排除)
同じ値が何度も出てくる列から、ユニークな値だけを取り出すときに使います。
例えば、部署名の一覧を取得したい場合は、以下の通りになります。
▼例:部署名の一覧を取得する場合
SELECT DISTINCT department
FROM users;▼実行結果

| department |
|---|
| Tech |
| Sales |
usersにTechが2人いても、重複せず1回だけ表示するのがDITINCTだよ。
NULL(空欄の扱い)
SQLでは、データが入っていない場合「NULL」として扱われます。
NULLは「0」や「空文字」とは違い、「値が存在しない」という意味です。
NULLをそのままにすると計算でエラーになることもあるため、COALESCE関数で置き換えするのが便利です。
例えば、先程のデータで「注文金額がNULLなら0として表示したい」場合は、以下のように入力します。
▼例:注文金額がNULLなら0として表示する場合
SELECT users.name, COALESCE(orders.amount, 0) AS amount
FROM users
LEFT JOIN orders
ON users.id = orders.user_id;▼実行結果
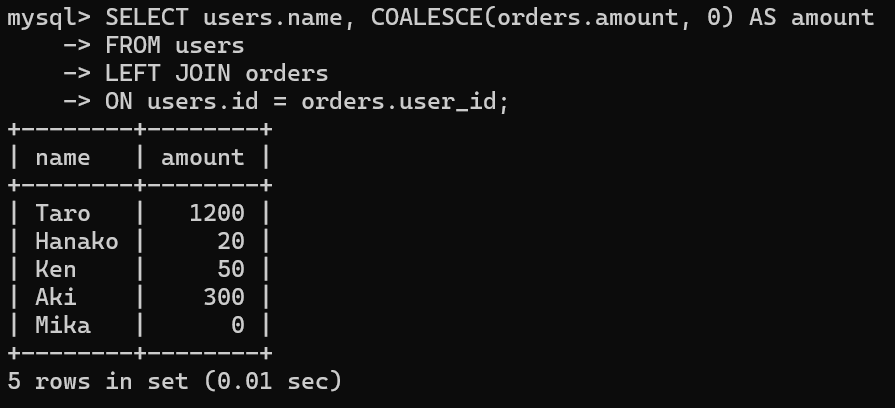
| name | amount |
|---|---|
| Taro | 1200 |
| Hanako | 20 |
| Ken | 50 |
| Aki | 300 |
| Mika | 0 |
「NULL」が「0」になっていれば、置き換えができています。
DISTINCTは重複を消せるし、COALESCEでNULLを0にできるのか!便利だね!
そうそう!SQLではNULLをどう扱うかは重要だから、最初に押さえておくと安心だよ!
まとめ:基礎構文を覚えてSQLに触れていこう!

データ分析で成果を出すためには、まずSQLの基礎を理解して使えるようになることが大切です。
今回の記事では、以下の内容を解説しました。
- データ分析でSQLが必要な理由
- SQLの基本(抽出・集計・結合という役割)
- 基礎構文(SELECT/WHERE/ORDER BY/GROUP BY/HAVING/JOIN/DISTINCT・NULL)
- 基礎構文を組み合わせたコード例
SQLの基礎を押さえることで、Excelでは扱えないような大規模データでも素早く処理できるようになり、分析のスピードと精度が一気に向上します。
さらに、分析の幅が広がり「データで語れる」力が身につくことで、データアナリストとして質も上がっていきます。
最初は難しそうに感じたけど、SELECT → GROUP BY → JOIN の流れを押さえれば、意外とシンプルなんだね!
まずはこの記事で紹介したサンプルを動かして“書けた!”という感覚を積み上げていこう!
以上、とめでした!
▼勉強時間を捻出する方法

▼キャリア設計のやり方

▼目標設定の作り方

▼未経験からデータアナリストになる心構え

▼未経験からデータアナリストになるための10ヶ条
▼SQLの始め方


コメント